SQLAlchemy 2.0: Modern ve Asenkron Veritabanı Yönetimi
ORM kullanmak performans öldürür mü? N+1 problemini çözemezseniz evet. SQLAlchemy 2.0, AsyncSession ve ileri seviye optimizasyon teknikleri.
Birçok Senior Developer “Raw SQL yazalım, ORM yavaştır” der. Bu genellikle ORM’in yanlış kullanımından kaynaklanan, yıllar öncesinden kalma bir ön yargıdır. ORM (Object Relational Mapping), SQL Injection riskini azaltır, kod tekrarını önler ve veritabanı bağımsızlığı sağlar. PostgreSQL’den MySQL’e geçmek, ORM kullanıyorsanız sadece Connection String değiştirmektir. Raw SQL’de ise tüm projeyi yeniden yazmaktır. Ayrıca CRUD işlemleri için sürekli INSERT INTO ... yazmak zaman kaybıdır. Ancak, “Lazy Loading” tuzağına düşerseniz, performansınız yerle bir olur. Veritabanı sunucusu %100 CPU ile ağlar.
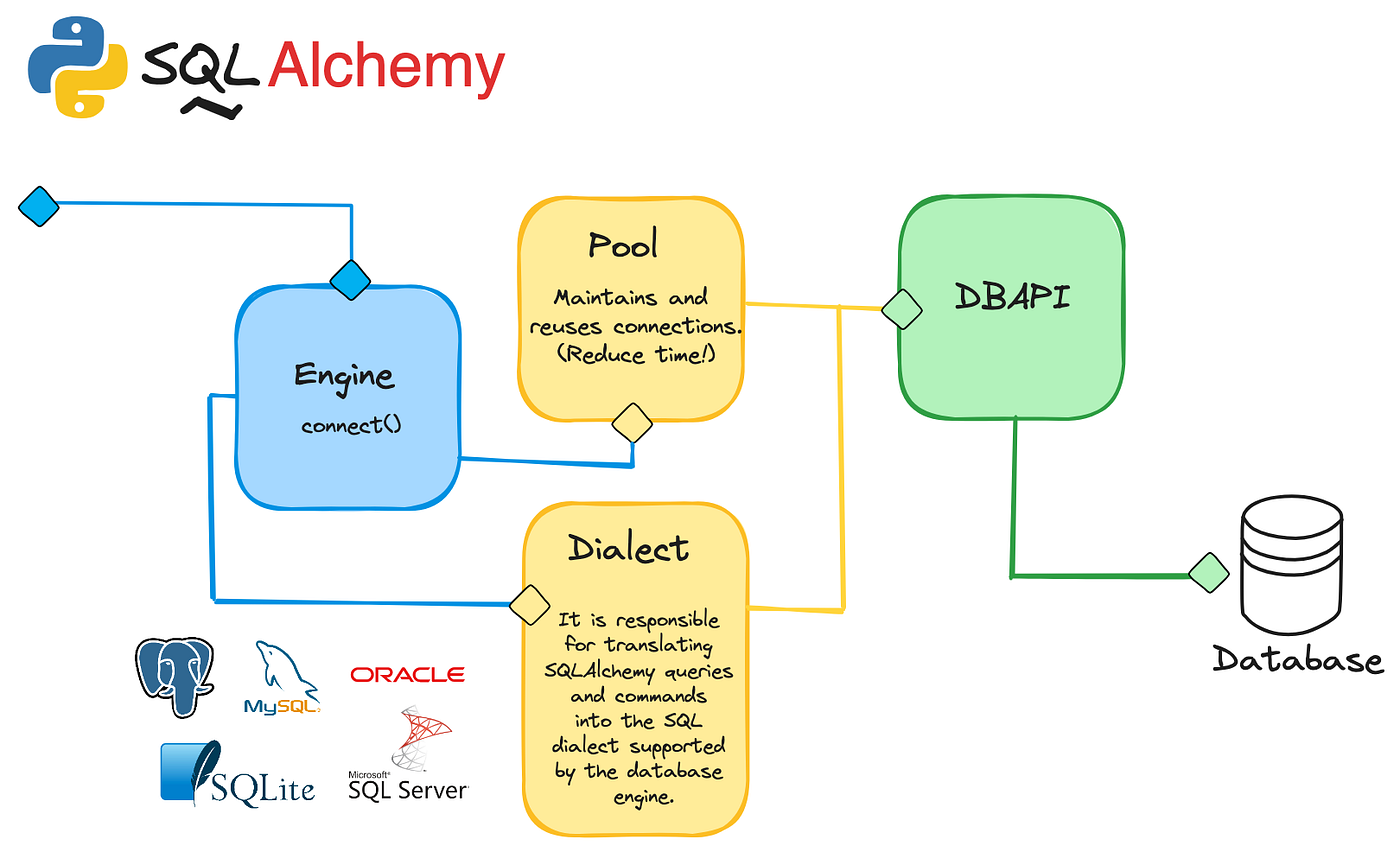
SQLAlchemy 2.0 ile gelen tam asenkron destek (AsyncSession), mypy uyumlu yeni tip sistemi ve modern sorgu sözdizimi (select()), Python backend dünyasında kartları yeniden dağıtıyor. Artık hem tip güvenliğine (type safety) sahibiz hem de asenkron I/O performansına.
 Engine -> Connection Pool -> AsyncSession -> Transaction döngüsü.
Engine -> Connection Pool -> AsyncSession -> Transaction döngüsü.
1. Modern Syntax: Session.query() Bitti
Eski SQLAlchemy sürümlerinde (1.4 öncesi) session.query(User).filter(...) kullanırdık. 2.0 sürümü ile birlikte bu yapı “Legacy” (Eski) olarak işaretlendi. Artık Core ve ORM API’ları birleşti. Standart SQL’e çok daha yakın, tutarlı bir yapıya geçtik:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from sqlalchemy import select
from sqlalchemy.ext.asyncio import AsyncSession
async def get_active_users(session: AsyncSession):
# Modern 2.0 Syntax: select() yapısı
# where() ile filtrele, order_by() ile sırala
stmt = (
select(User)
.where(User.is_active == True)
.where(User.age > 18)
.order_by(User.created_at.desc())
)
# execute() ile sorguyu asenkron çalıştır
result = await session.execute(stmt)
# scalars() ile ORM nesnelerini (User) al, all() ile listeye çevir
# unique() çağrısı joinedload kullanıldığında gerekebilir
return result.scalars().all()
Bu yeni yapı, type-hinting (Tip denetimi) araçlarıyla çok daha iyi çalışır. IDE’niz artık stmt değişkeninin ne olduğunu daha iyi anlar. Eskiden query objesinin ne döndüreceğini tahmin etmek zordu, şimdi Result objesi net bir API sunar. Ayrıca, await keyword’ü ile I/O bloklanmasının önüne geçeriz. 1000 kullanıcıyı çekerken (200ms sürsün), CPU’nuz durup beklemez, gidip başka bir isteğe cevap verir. Node.js ve Go’nun varsayılan olarak yaptığı şeyi, Python’da biz açıkça yaparız. Yüksek trafikli (High Concurrency) uygulamalarda Sync vs Async farkı, sunucu maliyetinizi yarıya indirebilir.
2. N+1 Problemi: Sessiz Katil
ORM’lerin en büyük düşmanı ve performans sorunlarının %90’ının kaynağı N+1 problemidir. Basit bir senaryo düşünelim: 100 adet siparişi listeliyorsunuz. Her siparişin yanında, o siparişi veren kullanıcının adını (order.user.name) göstermek istiyorsunuz.
Kodunuz şöyle çalışır:
- Tüm siparişleri çek (1 SQL Sorgusu). “SELECT * FROM orders”.
- Döngüye gir. Her sipariş için
order.userdediğinizde, ORM gidip o user ID için veritabanına bir sorgu daha atar.- Sipariş 1 için User A’yı getir (Sorgu 2).
- Sipariş 2 için User B’yi getir (Sorgu 3).
- …
- Sipariş 100 için User Z’yi getir (Sorgu 101).
Toplam: 101 Sorgu. Veritabanı Yöneticisi (DBA) bu logları gördüğünde sizi odasına çağırır. Ve sisteminiz kullanıcı sayısı arttıkça değil, karesiyle yavaşlar. Çözüm: Eager Loading (Peşin Yükleme). Veriyi isterken ilişkili tabloları da isteyin.
1
2
3
4
5
6
7
8
9
from sqlalchemy.orm import selectinload, joinedload
# Tek sorguda siparişleri VE kullanıcıları çek
# options() fonksiyonu ile yükleme stratejisini belirle
stmt = (
select(Order)
.options(selectinload(Order.user)) # Kullanıcıları da getir
.options(joinedload(Order.items)) # Sipariş kalemlerini de getir
)
SQLAlchemy’de iki ana strateji vardır:
joinedload: SQLJOINkullanır. Tek bir dev sorgu atar. Many-to-One ilişkilerde (Sipariş -> User) harikadır çünkü veri tekrarı azdır.selectinload: İkincil birSELECT ... WHERE IN (...)sorgusu atar. One-to-Many (User -> Siparişler) ilişkilerde ve Async ortamda daha performanslıdır. Çünkü asenkron olarak ikinci sorguyu beklemek maliyetsizdir ve “Cartesian Product” (Kartezyen çarpım) sorununu önler. 1000 sipariş için 5000 kalem varsa, JOIN yapıldığında 5000 satır döner, bu da veri transferini şişirir.
 100 satırlık veri için 101 sorgu atmak vs Eager Loading ile 2 sorgu atmak.
100 satırlık veri için 101 sorgu atmak vs Eager Loading ile 2 sorgu atmak.
3. Veritabanı Migrasyonları: Alembic
Kodunuzda User tablosuna age kolonu eklediniz. Kodunuzu sunucuya attınız. Uygulama çöktü. Neden? Çünkü veritabanında age kolonu fiziksel olarak yok. Sakın production veritabanına pgAdmin/DBeaver ile girip ALTER TABLE yazmayın. Bu, felakete davetiyedir. Ya komutu yanlış yazarsanız? Ya production’ı kilitlerseniz? Alembic, veritabanı şemanızın versiyon kontrol sistemidir (git gibi). Şemanızın evrimini yönetir.
alembic revision --autogenerate -m "add age column": Alembic, Python modellerinizi tarar, canlı DB şeması ile karşılaştırır ve farkı bulur.- Otomatik bir Python dosyası (Migration Script) oluşturur. Bu dosyayı inceleyin (Review). Bazen isim değişikliklerini
DROP TABLE+CREATE TABLEsanabilir. Verinizi kaybetmeyin. alembic upgrade head: Değişiklikleri veritabanına uygula.
Bu sayede, veritabanı şemanız her zaman kodunuzla senkronize kalır. Yeni bir geliştirici ekibe katıldığında alembic upgrade head der ve veritabanı sıfırdan en güncel haline gelir. Ayrıca bir şeyler ters giderse alembic downgrade -1 ile değişikliği geri alabilirsiniz. Bu deployment güvenliği için kritiktir.
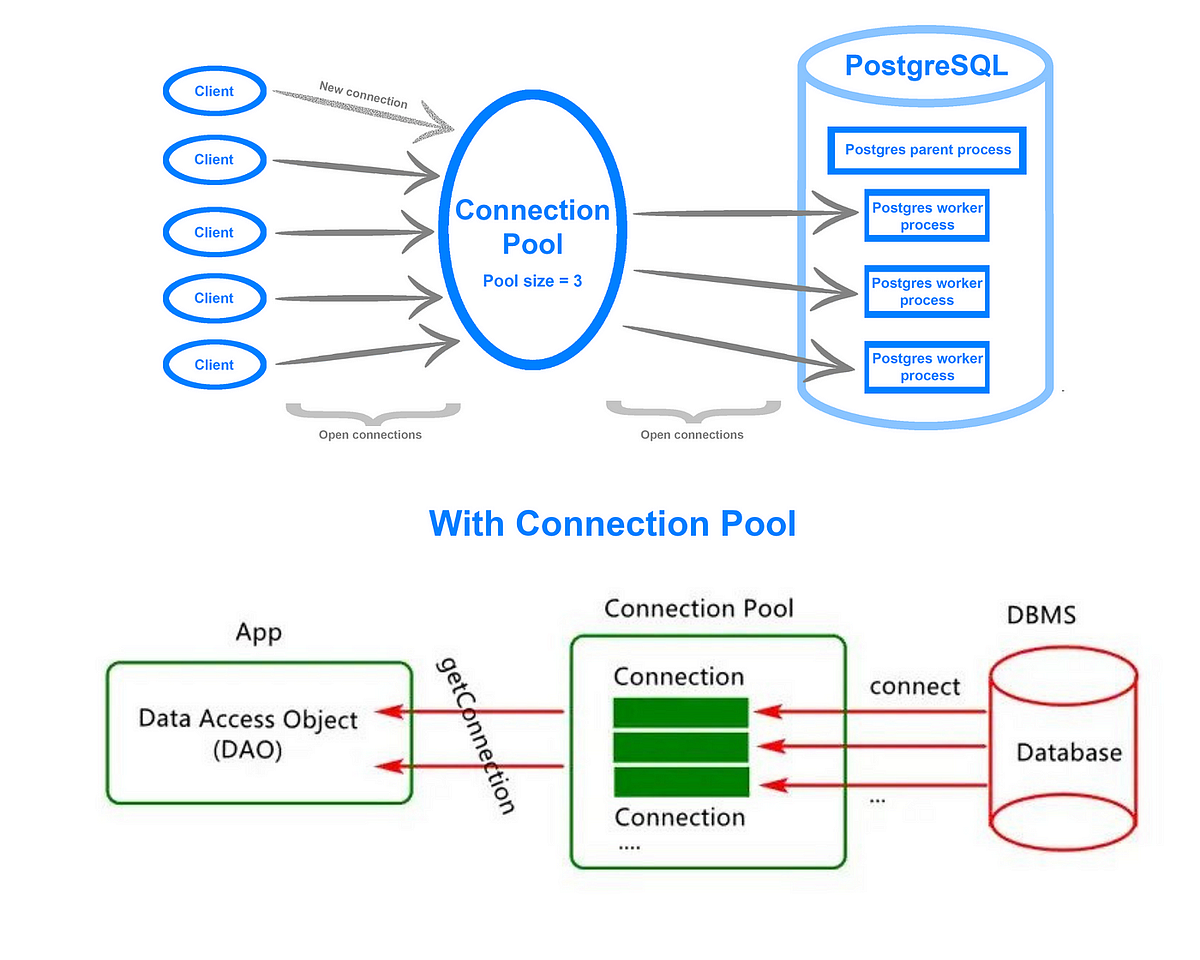
4. Connection Pooling: Havuzu Taşırma
Her HTTP isteği için veritabanına “Merhaba, ben geldim” deyip yeni bağlantı (TCP Handshake + Authentication) açmak çok pahalıdır (50-100ms sürer). Yüksek trafikli bir sistemde bu gecikme kabul edilemez. Connection Pooling, veritabanı ile uygulama arasında hazırda bekleyen, açık bağlantılardan oluşan bir havuzdur. İstek geldiğinde havuzdan bir bağlantı ödünç alınır, iş bitince havuza iade edilir.
SQLAlchemy AsyncEngine oluştururken ayarları doğru yapın:
1
2
3
4
5
6
7
8
engine = create_async_engine(
DATABASE_URL,
pool_size=20, # Havuzda sürekli açık duracak çekirdek bağlantı sayısı
max_overflow=10, # Yoğunluk anında geçici olarak açılacak ek bağlantı (esneme payı)
pool_timeout=30, # Havuz boşsa, bağlantı boşa çıkana kadar kaç saniye beklesin? (Hata vermeden önce)
pool_recycle=1800, # Bağlantıyı 30 dakikada bir yenile (Stale connection/Firewall drop önlemi)
pool_pre_ping=True # Bağlantıyı almadan önce "SELECT 1" atıp canlı mı diye kontrol et (Ölü bağlantı hatasını önler)
)
Eğer loglarınızda “Timeout: QueuePool limit of size 20 overflow 10 reached” hatası görüyorsanız, durum ciddidir.
- Trafiğiniz gerçekten çok artmıştır (İyi haber, pool’u büyütün).
- Daha kötüsü, uygulamanızda “Connection Leak” vardır. Bir yerde
sessionalıp, iş bitinceclose()etmiyorsunuzdur (veya context manager kullanmıyorsunuzdur). Havuzdaki tüm bağlantılar “Meşgul” görünür ve sistem kilitlenir. - Asenkron olmayan bir kütüphane kullanıp veritabanını blokluyorsunuzdur.
 Model değişikliği -> Revision oluşturma -> Review -> Upgrade.
Model değişikliği -> Revision oluşturma -> Review -> Upgrade.
5. Declarative Base ve Mypy Entegrasyonu
SQLAlchemy 2.0 ile model tanımlama şeklimiz de değişti. Artık Python’un yerleşik type hints yapısını tamamen destekleyen Mapped ve mapped_column kullanıyoruz. Bu sayede statik kod analizi araçları (Mypy, Pyright) hatalarımızı development aşamasında yakalayabiliyor.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column
from sqlalchemy import String
from datetime import datetime
class Base(DeclarativeBase):
pass
class User(Base):
__tablename__ = "users"
id: Mapped[int] = mapped_column(primary_key=True)
username: Mapped[str] = mapped_column(String(50), unique=True)
email: Mapped[str] = mapped_column(String(100))
created_at: Mapped[datetime] = mapped_column(default=datetime.utcnow)
Bu kod, eski Column(Integer, PrimaryKey=True) yapısına göre çok daha temiz ve okunabilirdir. Ayrıca, Mapped[int] sayesinde IDE’niz user.id‘nin bir integer olduğunu bilir ve string operasyonları yapmanızı engeller.
 Client -> Application (Pool) -> Database. Bağlantı tekrar kullanımı ve performans etkisi.
Client -> Application (Pool) -> Database. Bağlantı tekrar kullanımı ve performans etkisi.
6. İndeksleme: Görünmez Kahraman
ORM kullanırken yapılan en büyük hata, indekslerin veritabanı tarafında otomatik oluşacağını sanmaktır. primary_key=True bir indeks oluşturur, ancak filter(User.age > 18) dediğinizde age üzerinde indeks yoksa “Full Table Scan” yapılır. SQLAlchemy modelinde indeksleri açıkça tanımlamalısınız:
1
2
3
4
5
6
7
8
9
10
from sqlalchemy import Index
class User(Base):
__tablename__ = "users"
# ... kolonlar ...
# Composite Index: İsim ve Soyisime göre sık arama yapılıyorsa
__table_args__ = (
Index('idx_user_name_surname', 'first_name', 'last_name'),
)
Bu tanım, Alembic ile migration oluşturduğunuzda CREATE INDEX komutuna dönüşür. Unutmayın, production veritabanında yavaş bir sorguyu düzeltmek için kod değiştirmeden sadece indeks eklemek çoğu zaman hayat kurtarır.
Sonuç
Veri, uygulamanızın en değerli varlığıdır. Kodunuz değişir, sunucularınız değişir ama veriniz kalıcıdır. Onu yöneten katman (ORM) “Magic” (Sihir) gibi görünse de, arkada dönen SQL’i bilmek zorundasınız. Soyutlama (Abstraction), detayları bilmeme özgürlüğü değildir; detayları yönetme kolaylığıdır. SQLAlchemy 2.0’ın asenkron gücünü sonuna kadar kullanın, ama N+1 gibi tuzaklara düşmemek için geliştirme ortamında echo=True yaparak arada bir consol’a düşen sorgulara göz atın. Hızlı kod yazmak değil, hızlı çalışan ve bakımı kolay kod yazmak gerçek mühendisliktir. Ve her zaman hatırda tutun: En hızlı sorgu, hiç atılmayan sorgudur (bkz: Caching).