Apache Kafka: Event Streaming ve Gerçek Hayat Tuzakları
Kafka sadece bir mesaj kuyruğu değildir. 'Log Compaction', 'Rebalancing' krizleri ve Production ortamında ayakta kalma rehberi.
Saat gece 03:00. Telefonunuz çalıyor. “Black Friday” kampanyasının ortasındasınız ve Sipariş Servisi çökmüş. Loglara bakıyorsunuz: Servis çalışıyor ama siparişler veritabanına düşmüyor. Suçlu? Muhtemelen yanlış yapılandırılmış bir Apache Kafka cluster’ı. Kafka, doğru kurulduğunda saniyede milyonlarca olayı (Event) işleyebilen bir canavardır. Yanlış kurulduğunda ise, “Rebalancing Storm” içinde kaybolan verilerin mezarlığına dönüşür.
Bu yazıda dokümantasyonda yazanları değil, production ortamında canımızı yakan gerçek senaryoları ve çözüm yollarını konuşacağız.
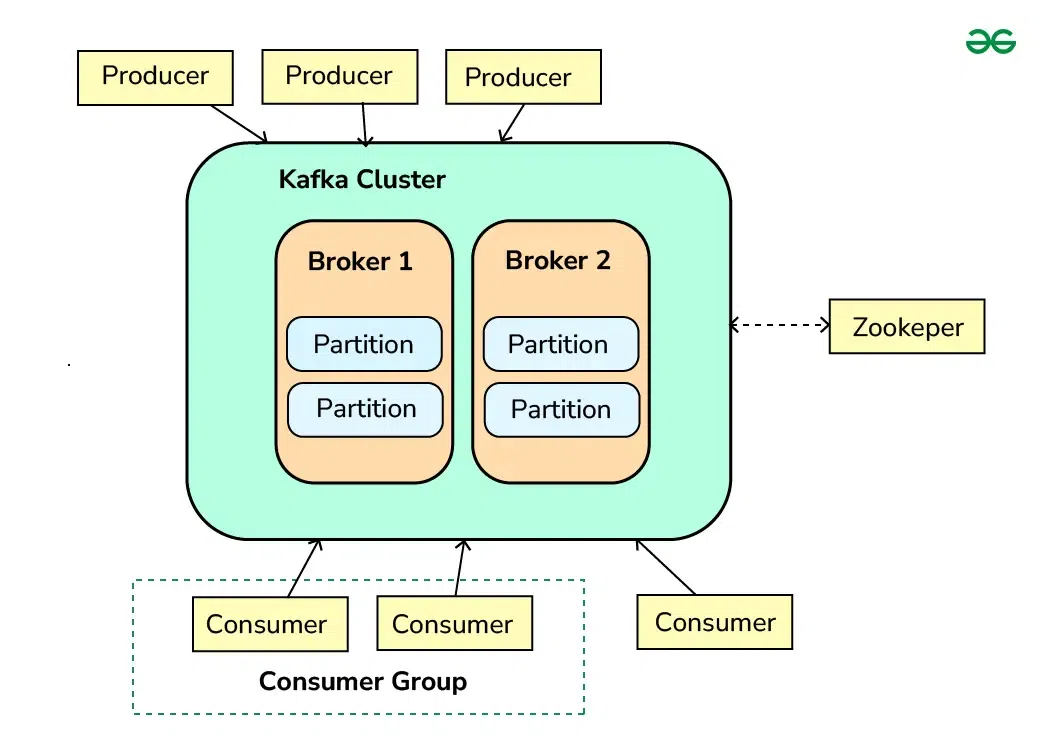 Producer -> Topic (Broker) -> Consumer akışı ve Partition yapısı.
Producer -> Topic (Broker) -> Consumer akışı ve Partition yapısı.
1. Mimari Uyuşmazlık: Kafka vs RabbitMQ
Çoğu yazılımcı Kafka’yı “Hızlı bir RabbitMQ” sanır. Bu büyük bir hatadır. RabbitMQ (Smart Broker, Dumb Consumer): Broker zekidir. Mesajı kime ileteceğini bilir, Consumer’dan “aldım” onayı gelince mesajı siler. Kafka (Dumb Broker, Smart Consumer): Broker aptaldır (Sadece bir Log dosyasıdır). Mesajı silmez (Retention süresi bitene kadar). Nerede kaldığını (Offset) Consumer kendisi takip etmek zorundadır.
Neden Önemli? Eğer Pub/Sub yapıyorsanız ve geçmişe dönük veriyi tekrar işlemek (Replay) istiyorsanız Kafka rakipsizdir. Ama “İşlenen mesaj anında yok olsun, karmaşık routing (Routing Key) yapayım” diyorsanız RabbitMQ kullanmalısınız. Örneğin, IoT verisi alıyorsanız ve milyonlarca sensörden gelen veriyi sırayla ve kayıpsız işlemeniz gerekiyorsa, RabbitMQ bu yükün altında ezilebilir; Kafka ise tam da bunun için tasarlanmıştır.
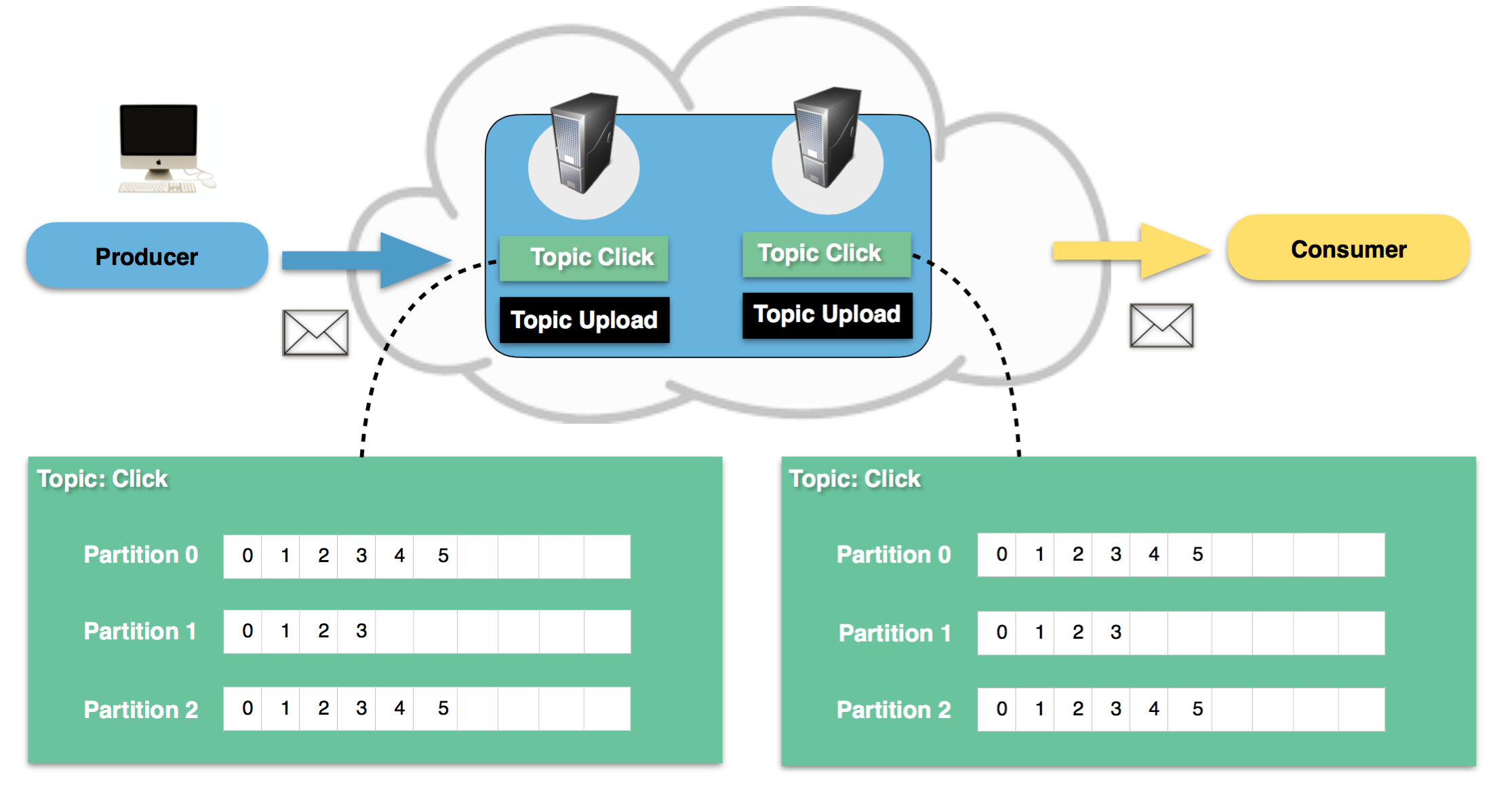
2. Kapasite Planlaması: Partition Sayısı Hesabı
Kafka’yı kurarken yapılan en kritik hata, rastgele partition sayısı vermektir. Partition sayısı, Parallelism (Paralellik) limitinizi belirler. Eğer partition=3 derseniz, aynı anda en fazla 3 consumer bu topic’i okuyabilir. 4. consumer boşta bekler (Idle).
Formül: Hedeflediğiniz yazma hızı (Throughput) ve tüketme hızına göre hesaplanmalıdır. Partition Sayısı = Max(Hedef Throughput / Tek Producer Hızı, Hedef Throughput / Tek Consumer Hızı)
Senaryo: Saniyede 1000 mesaj geliyor. Tek bir consumer saniyede 100 mesaj işleyebiliyor (DB işlemleri vs.). O zaman size en az 1000 / 100 = 10 partition lazım ki 10 consumer paralel çalışıp kuyruğu eritebilsin.
3. Operasyonel Kâbuslar: ZooKeeper ve Disk I/O
Kafka (versiyon 2.8 öncesi) ZooKeeper olmadan çalışmaz. Bu da yönetmeniz gereken ikinci bir Cluster (“Distributed System”) demektir. Neyse ki KRaft (Kafka Raft Metadata) modu ile ZooKeeper bağımlılığı kalkıyor ama çoğu legacy sistem hala ZK ile çalışır.
Bir diğer tuzak: Disk I/O. Kafka diske sıralı yazar (Sequential Write). Bu mekanik disklerde bile çok hızlıdır. Ama loglarınızın Retention süresi dolduğunda, Kafka eski segmentleri silmek (veya Compact etmek) için diske yüklenir. Eğer disk IOPS limitine takılırsanız, Producer’larınız “Timeout” almaya başlar ve sistem durur. SSD kullanmak bir “lüks” değil, zorunluluktur. Ayrıca log dizinlerinizi (log.dirs) birden fazla diske yaymak (JBOD) performansı artırır.
4. Configuration Tuning: Hız mı, Güvenlik mi?
Varsayılan Kafka ayarları “Maksimum Hız” için optimize edilmiştir, “Sıfır Veri Kaybı” için değil. Finansal bir işlem yapıyorsanız şu ayarları değiştirmelisiniz:
acks=all(Producer): Mesaj sadece Leader partition’a değil, tüm replikalara (ISR) yazılana kadar “başarılı” sayılmaz.min.insync.replicas=2(Broker): En az 2 sunucuya yazılmadan onay verme. Tek sunucu ölürse veri kaybolmaz.enable.auto.commit=False(Consumer): Mesajı aldım diye hemen Kafka’ya bildirme. İşlemen (DB’ye yazman) bitince manuel commit et.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# Güvenilir Producer Örneği
from kafka import KafkaProducer
import json
producer = KafkaProducer(
bootstrap_servers=['broker1:9092'],
value_serializer=lambda v: json.dumps(v).encode('utf-8'),
acks='all', # En güvenli mod
retries=5, # Hata olursa 5 kere dene
linger_ms=10 # Mesajları 10ms biriktir (Batching)
)
def on_send_success(record_metadata):
print(f"Message sent to {record_metadata.topic} partition {record_metadata.partition}")
# Asenkron gönderim
producer.send('my-topic', {'key': 'value'}).add_callback(on_send_success)
 Consumer Group ölçeklemesi: Her tüketici bir partition’dan sorumludur.
Consumer Group ölçeklemesi: Her tüketici bir partition’dan sorumludur.
5. Consumer Group Rebalancing Krizi
Kafka’nın en korkulan olayıdır: Stop-the-World Rebalance. Bir Consumer grubuna yeni bir üye katıldığında veya biri öldüğünde, Kafka durur ve partitionları yeniden dağıtır. Eğer max.poll.interval.ms süresinde mesajı işleyemezseniz (örneğin DB yavaşladı), Kafka sizi “öldü” sanar ve gruptan atar.
Çözüm Stratejileri:
session.timeout.msdeğerini artırın (Örn: 45sn).max.poll.recordssayısını düşürün. Bir seferde 500 yerine 50 mesaj çekin.- Static Membership: Tüketicilere sabit bir
group.instance.idverin. Böylece kısa süreli kopmalarda (restart) Kafka rebalance yapmaz, “geri gelecek” diye bekler.
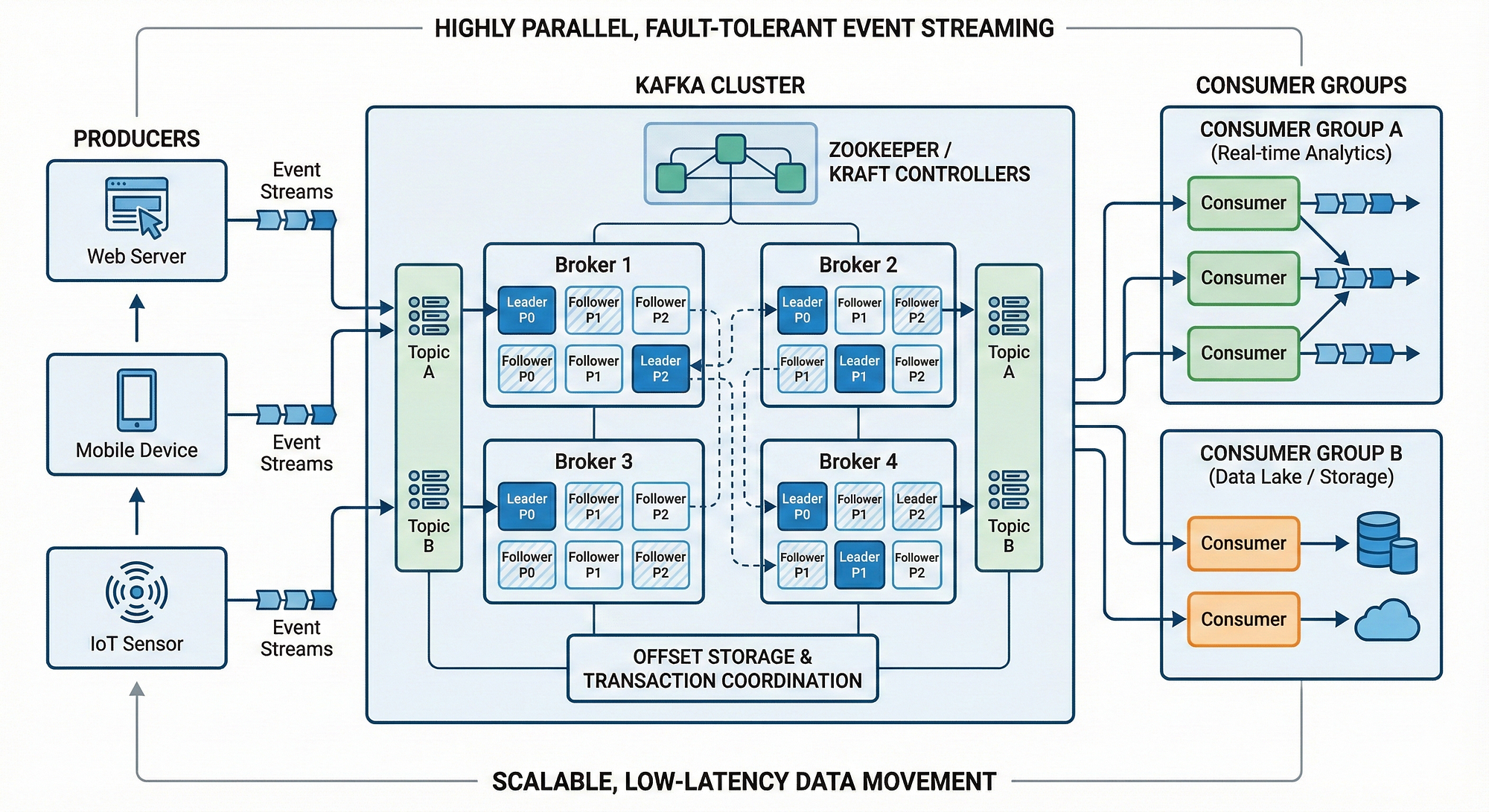 Offset Commit stratejileri: At-most-once vs At-least-once.
Offset Commit stratejileri: At-most-once vs At-least-once.
6. Log Compaction ve State Store
Kafka’nın az bilinen süper gücü: Log Compaction. Normalde eski loglar silinir. Ama cleanup.policy=compact derseniz, Kafka sadece “En son değeri” saklar. Örneğin “User:123” için “Ad: Ahmet” sonra “Ad: Mehmet” geldiyse, Ahmet silinir. Bu özellik sayesinde Kafka, bir Key-Value veritabanı (Event Store) gibi davranabilir. Mikroservisler açılırken tüm state’i buradan yükleyebilir (Event Sourcing).
7. Sık Yapılan Hatalar (Anti-Patterns)
Kariyerim boyunca gördüğüm en maliyetli hatalar:
- Her İsteğe Yeni Producer: Producer nesnesi ağırdır, thread-safe’dir ve connection pool yönetir. Global tek bir instance (Singleton) olarak kullanılmalıdır. Her request’te
KafkaProducer()çağırırsanız sunucuyu öldürürsünüz. - Büyük Mesajlar (Large Payloads): Kafka’ya resim/video (blob) atılmaz. Kafka’ya sadece referans (S3 URL) atılır. Default limit 1MB’dır ve bunu artırmak performansı çökertir.
- Aşırı Topic Sayısı: Binlerce topic yaratmak, ZooKeeper ve Controller üzerinde inanılmaz yük oluşturur. Mümkünse benzer verileri aynı topic altında toplayın.
8. İzleme ve Alarm (Monitoring)
Kafka kör uçuş yapılacak bir sistem değildir. Mutlaka izlemeniz gereken metrikler:
- Consumer Lag: Tüketici ne kadar geriden geliyor? En kritik metriktir.
- Under Replicated Partitions: Veri risk altında mı?
- Active Controller Count: Cluster’da sadece 1 tane olmalı.
- Request Handler Idle Percent: Broker’lar ne kadar yoğun?
Burrow veya Prometheus JMX Exporter kullanarak bu metrikleri Grafana’ya aktarmalısınız.
Kritik PromQL Sorguları
Grafana dashboard’unuzda mutlaka olması gereken alarmlar:
- Consumer Group Lag (En kritik):
kafka_consumergroup_group_lag > 1000Anlamı: Tüketici 1000 mesaj geriden geliyor. Acil müdahale (Scale up) lazım.
- Under Replicated Partitions:
kafka_server_ReplicaManager_UnderReplicatedPartitions > 0Anlamı: Bir broker çöktü veya ağ koptu. Veri yedeklenemiyor, risk altındasınız.
- Active Controller Count:
kafka_controller_KafkaController_ActiveControllerCount != 1Anlamı: Split-brain durumu. Sistemde ya hiç yönetici yok ya da iki yönetici kavga ediyor.
9. Gerçek Bir Veri Kaybı Hikayesi
Bir e-ticaret firmasında “Unclean Leader Election” ayarının true unutulduğu bir senaryo yaşadık. Bir gece, Leader olan Broker-1’in diski arızalandı. Normalde Kafka, senkronize (ISR) olan Broker-2’yi yeni Leader yapmalıydı. Ancak Broker-2 de ağ sorunu yüzünden geride kalmıştı (Out of sync). unclean.leader.election=true olduğu için Kafka dedi ki: “Veri kaybı, sistemin durmasından iyidir.” Ve güncel olmayan Broker-2’yi Leader yaptı. Sonuç: Son 5 dakikadaki tüm siparişler silindi. Yaklaşık 40.000 TL ciro buhar oldu. Ders: Finansal sistemlerde unclean.leader.election=false ZORUNLUDUR. Sistem durmalı ama veri kaybetmemelidir.
10. Sık Sorulan Sorular (SSS)
S: Partition sayısı sonradan artırılır mı? C: Evet artırılabilir ama azaltılamaz. Artırdığınızda da Key-based ordering bozulabilir (Aynı key farklı partition’a gidebilir).
S: Kafka DB yerine geçer mi? C: Hayır. Belli bir süre (Retention) için veriyi tutar. Ancak Log Compaction ile sınırlı bir K/V store gibi davranabilir.
S: Mesaj sıralaması (Ordering) garanti mi? C: Sadece partition bazında garantidir. Topic genelinde garanti değildir.
Terimler Sözlüğü (Glossary)
- Broker: Kafka sunucusu.
- Topic: Mesajların tutulduğu kategori.
- Partition: Ölçeklenebilirlik birimi.
- Offset: Mesajın sıra numarası.
- Replication Factor: Verinin kaç kopyasının tutulacağı.
- ISR (In-Sync Replicas): Güncel kopyalar.
Sonuç
Apache Kafka, büyük veri dünyasının ağır siklet şampiyonudur. Sadece “Haberleşme” için kullanacaksanız overkill olabilir. Ama veri tutarlılığı, ölçeklenebilirlik ve geçmişe dönük işlem yapabilme yeteneği (Replayability) sizin için kritikse, Kafka öğrenmeye ayıracağınız her dakikaya değer. Doğru yapılandırılmış bir Kafka cluster’ı, geceleri rahat uyumanızı sağlar.
Gerçek dünyada Kafka: Log Aggregation, Stream Processing ve Event Sourcing.